Données spatiales: découverte de geopandas
Dans ce tutoriel, nous allons utiliser:
La représentation des données, notamment la cartographie, est présentée plus amplement dans la partie visualiser.
Ce tutoriel s’inspire beaucoup d’un autre tutoriel que j’ai fait pour R lien utilitR. Il peut servir de pendant à celui-ci pour l’utilisateur de R.
import geopandas as gpd
#import contextily as ctx
Données spatiales: quelle différence avec des données traditionnelles ?
Le terme “données spatiales” désigne les données qui portent sur les caractéristiques géographiques des objets (localisation, contours, liens). Les caractéristiques géographiques des objets sont décrites à l’aide d’un système de coordonnées qui permetent une représentation dans un espace euclidien ($(x,y)$). Le passage de l’espace réel (la Terre, qui est une sphère) à l’espace plan se fait grâce à un système de projection. Voici quelques exemples de données spatiales:
- Une table décrivant des bâtiments, avec les coordonnées géographiques de chaque bâtiment;
- Le découpage communal du territoire, avec le contour du territoire de chaque commune;
- Les routes terrestres, avec les coordonnées décrivant leur parcours.
Les données spatiales rassemblent classiquement deux types de données :
- des données géographiques (ou géométries): objets géométriques tels que des points, des vecteurs, des polygones, ou des maillages (raster). Exemple: la forme de chaque chaque commune, les coordonnées d’un bâtiment;
- des données attributaires (ou attributs): des mesures et des caractéristiques associés aux objets géométriques. Exemple: la population de chaque commune, le nombre de fenêtres et le nombre d'étages d’un bâtiment.
Les données spatiales sont fréquemment traitées à l’aide d’un système d’information géographique (SIG), c’est-à-dire un système d’information capable de stocker, d’organiser et de présenter des données alphanumériques spatialement référencées par des coordonnées dans un système de référence (CRS). R dispose de fonctionnalités lui permettant de réaliser les mêmes tâches qu’un SIG (traitement de données spatiales, représentations cartographiques).
**Les systèmes de projection font l’objet de standards internationaux et sont souvent désignés par des codes dits codes EPSG **. Ce site est un bon aide-mémoire. Les plus fréquents, pour les utilisateurs français, sont les suivants (plus d’infos ici):
2154: système de projection Lambert 93. Il s’agit du système de projection officiel: la plupart des données diffusées par l’administration pour la métropole sont disponibles dans ce système de projection.4326: WGS 84 ou système de pseudo-Mercator. C’est le système de projection des données GPS.
27572: Lambert II étendu. Il s’agit de l’ancien système de projection officiel. Les données spatiales anciennes peuvent être dans ce format.
De pandas à geopandas
Le package geopandas est une boîte à outils conçue pour faciliter la manipulation de données spatiales. La grande force de geopandas est qu’il permet de manipuler des données spatiales comme s’il s’agissait de données traditionnelles, car il repose sur le standard ISO 19125 simple feature access défini conjointement par l’Open Geospatial Consortium (OGC) et l’International Organization for Standardization (ISO).
Par rapport à un DataFrame standard, un objet geopandas comporte
une colonne supplémentaire: geometry. Elle stocke les contours des
objets géographiques. Un objet geopandas hérite des propriétés d’un
DataFrame pandas mais propose des méthodes adaptées au traitement des données
spatiales
Ainsi, grâce à geopandas, on pourra effectuer des manipulations sur les attributs des données comme avec pandas mais on pourra également faire des manipulations sur la dimension spatiale des données. En particulier,
- Calculer des distances et des surfaces;
- Agréger rapidement des zonages (regrouper les communes en département par exemple);
- Trouver dans quelle commune se trouve un bâtiment à partir de ses coordonnées géographiques;
- Recalculer des coordonnées dans un autre système de projection.
- Faire une carte, rapidement et simplement
*conseil Les manipulations de données sur un objet geopandas sont nettement plus lentes que sur un DataFrame traditionnel (car python doit gérer les informations géographiques pendant la manipulation des données). Lorsque vous manipulez des données de grandes dimensions, il peut être préférable d’effectuer les opérations sur les données avant de joindre une géométrie à celles-ci.
Par rapport à un logiciel spécialisé comme QGIS, python permettra
d’automatiser le traitement et la représentation des données. D’ailleurs,
QGIS utilise lui-même python…
Importer des données spatiales
Les données spatiales sont plus riches que les données traditionnelles car elles incluent, habituellement, des éléments supplémentaires pour placer dans un espace cartésien les objets. Cette dimension supplémentaire peut être simple (un point comporte deux informations supplémentaire: $x$ et $y$) ou assez complexe (polygones, lignes avec direction, etc.)
Les formats les plus communes de données spatiales sont les suivants:
- shapefile (
.shp): format le plus commun de données géographiques. La table de données (attributs) est stockée dans un fichier séparé des données spatiales. En faisantgeopandas.read_file("monfichier.shp"), le package fait lui-même le lien entre les observations et leur représentation spatiale ; - geojson (
.json): la dimension spatiale est stockée dans le même fichier que les attributs. Ces fichiers sont généralement beaucoup plus légers et rapides à l’air que les shapefiles. Ils deviennent le format dominant. Lorsqu’on a le choix, il vaut mieux privilégier legeojsonau shapefile.
L’aide de geopandas propose des bouts de code en fonction des différentes situations dans lesquelles on se trouve.
Exemple: récupérer les découpages territoriaux
L’un des fonds de carte les plus fréquents qu’on utilise est celui des
limites administratives. Elles peuvent être trouvées sur le
site de l’IGN ou récupérées sur
data.gouv (construites par openstreetmap).
Nous prendrons la deuxième option car les premières données sont
compressés au format .7z, ce qui n’est pas pratique à dézipper avec
python (format propriétaire).
L’inconvénient est que les arrondissements
parisiens ne sont pas présents dans le fichier proposé sur data.gouv. Il
faut donc utiliser une source complémentaire, issue de l’opendata de la
Mairie de Paris.
Les données des limites administratives demandent donc un peu de travail pour être importées car elles sont zippées. Le code suivant, dont les détails apparaîtront plus clairs après la lecture de la partie webscraping permet
- Télécharger les données avec
requestsdans un dossier temporaire - Les dézipper avec le module
zipfile
La fonction suivante automatise un peu le processus:
import requests
import tempfile
import zipfile
url = 'https://www.data.gouv.fr/fr/datasets/r/07b7c9a2-d1e2-4da6-9f20-01a7b72d4b12'
temporary_location = tempfile.gettempdir()
def download_unzip(url, dirname = tempfile.gettempdir(), destname = "borders"):
myfile = requests.get(url)
open(dirname + '/' + destname + '.zip', 'wb').write(myfile.content)
with zipfile.ZipFile(dirname + '/' + destname + '.zip', 'r') as zip_ref:
zip_ref.extractall(dirname + '/' + destname)
download_unzip(url)
communes = gpd.read_file(temporary_location + "/borders/communes-20190101.json")
communes.head()
## insee ... geometry
## 0 97223 ... POLYGON ((-60.93595 14.58812, -60.93218 14.585...
## 1 97233 ... POLYGON ((-61.12165 14.71928, -61.11852 14.716...
## 2 97208 ... POLYGON ((-61.13355 14.74657, -61.13066 14.748...
## 3 97224 ... POLYGON ((-61.08459 14.72510, -61.08430 14.722...
## 4 97212 ... POLYGON ((-61.08459 14.72510, -61.08061 14.725...
##
## [5 rows x 5 columns]
On reconnaît la structure d’un DataFrame pandas. A cette structure s’ajoute
une colonne geometry qui enregistre la position des limites de chaque
observation.
Le système de projection est un élément crucial. Il permet à python
d’interpréter les valeurs des points (deux dimensions) en position sur
la terre, qui n’est pas un espace plan. La partie LIEN VERS SECTION
donne quelques détails supplémentaires. Ici, les données sont dans le
système WSG84 (epsg: 4326) ce qui permet de facilement ajouter
un fonds de carte openstreetmap ou stamen pour rendre une représentation
graphique plus esthétique (avec un autre système de projection, il
faudrait reprojeter les données, LIEN VERS SECTION).
On peut ainsi représenter Paris pour se donner une idée de la nature du shapefile utilisé :
paris = communes[communes.insee.str.startswith("75")]
ax = paris.plot(figsize=(10, 10), alpha=0.5, edgecolor='k')
#ctx.add_basemap(ax, crs = paris.crs.to_string())
ax

On voit ainsi que les données pour Paris ne comportent pas d’arrondissement, ce qui est limitant pour une analyse focalisée sur Paris. On va donc les récupérer sur le site d’open data de la ville de Paris et les substituer à Paris
arrondissements = gpd.read_file("https://opendata.paris.fr/explore/dataset/arrondissements/download/?format=geojson&timezone=Europe/Berlin&lang=fr")
arrondissements = arrondissements.rename(columns = {"c_arinsee": "insee"})
arrondissements['insee'] = arrondissements['insee'].astype(str)
communes = communes[~communes.insee.str.startswith("75")].append(arrondissements)
En refaisant la carte ci-dessus, on obtient bien, cette fois, le résultat espéré
paris = communes[communes.insee.str.startswith("75")]
ax = paris.plot(figsize=(10, 10), alpha=0.5, edgecolor='k')
#ctx.add_basemap(ax, crs = paris.crs.to_string())
ax

Opérations sur les attributs et les géométries
Import des données velib
Souvent, le découpage communal ne sert qu’en fond de cartes, pour donner des repères. En complément de celui-ci, on peut désirer exploiter un autre jeu de données. On va partir des données de localisation des stations velib, disponibles sur le site d’open data de la ville de Paris et requêtables directement par l’url https://opendata.paris.fr/explore/dataset/velib-emplacement-des-stations/download/?format=geojson&timezone=Europe/Berlin&lang=fr
velib_data = 'https://opendata.paris.fr/explore/dataset/velib-emplacement-des-stations/download/?format=geojson&timezone=Europe/Berlin&lang=fr'
stations = gpd.read_file(velib_data)
On peut se rassurer
communes['dep'] = communes.insee.str[:2]
ax = stations.sample(200).plot(figsize = (10,10), color = 'red', alpha = 0.4, zorder=2)
communes[communes['dep'].isin(['75','92','93','94'])].plot(ax = ax, zorder=1, edgecolor = "black", facecolor="none",
color = None)
# ctx.add_basemap(ax, crs = stations.crs.to_string(), source = ctx.providers.Stamen.Watercolor)

Opérations sur les attributs
Toutes les opérations possibles sur un objet pandas le sont également
sur un objet geopandas. Par exemple, si on désire
connaître quelques statistiques sur la taille des stations:
stations.describe()
## capacity
## count 1397.000000
## mean 31.404438
## std 12.149572
## min 0.000000
## 25% 23.000000
## 50% 29.000000
## 75% 37.000000
## max 74.000000
Par exemple pour connaître les plus grands départements:
communes.groupby('dep').sum().sort_values('surf_ha', ascending = False)
## surf_ha n_sq_co perimetre surface n_sq_ar c_ar
## dep
## 97 8936393.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 33 1008481.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 40 935359.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 24 922025.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 21 879892.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## .. ... ... ... ... ... ...
## 90 61048.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 94 24467.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 93 23674.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 92 17546.0 0.000000e+00 0.000000 0.000000e+00 0.000000e+00 0.0
## 75 0.0 1.500003e+10 190443.799631 1.053728e+08 1.500000e+10 210.0
##
## [97 rows x 6 columns]
ou les plus grandes communes de France métropolitaine :
communes[communes.dep != "97"].sort_values('surf_ha', ascending = False)
## insee nom ... c_ar dep
## 29861 13004 Arles ... NaN 13
## 29386 73290 Val-Cenis ... NaN 73
## 29632 13096 Saintes-Maries-de-la-Mer ... NaN 13
## 32467 49092 Chemillé-en-Anjou ... NaN 49
## 28877 49228 Noyant-Villages ... NaN 49
## ... ... ... ... ... ...
## 15 75113 NaN ... 13.0 75
## 16 75109 NaN ... 9.0 75
## 17 75118 NaN ... 18.0 75
## 18 75111 NaN ... 11.0 75
## 19 75116 NaN ... 16.0 75
##
## [34870 rows x 13 columns]
Lors des étapes d’aggrégation, groupby ne conserve pas les géométries.
Il est néanmoins possible d’aggréger à la fois les géométries et les
attribus avec la méthode dissolve:
communes[communes.dep != "97"].dissolve(by='dep', aggfunc='sum').plot(column = "surf_ha")

Opérations sur les géométries
⚠ Les données sont en système de projection WGS 84 ou pseudo-Mercator (epsg: 4326). C’est un format approprié lorsqu’il s’agit d’utiliser un fonds
de carte openstreetmap, stamen, google maps, etc. Mais ce n’est pas un
format sur lequel on désire faire des calculs car les distances sont faussées
avec cette projection. D’ailleurs, geopandas refusera certaines opérations
sur des données dont le crs est 4326. On reprojete ainsi les données
dans la projection officielle pour la métropole, le Lambert 93
(epsg: 2154). Plus de détails dans la partie LIEN SECTION
communes = communes.to_crs(2154)
stations = stations.to_crs(2154)
Outre la représentation graphique simplifiée, sur laquelle nous reviendrons
dans la partie LIEN PARTIE GEOPLOT, l’intérêt principal d’utiliser
geopandas est l’existence de méthodes efficaces pour
manipuler la dimension spatiale. Un certain nombre proviennent du
package
shapely.
Par exemple, on peut recalculer la taille d’une commune ou d’arrondissement
avec la méthode area (et diviser par $10^6$ pour avoir des $km^2$ au lieu
des $m^2$):
communes['superficie'] = communes.area.div(10**6)
communes
Une méthode qu’on utilise régulièrement est centroid qui transforme des
objets sous forme de polygones en un unique point. Par exemple, pour
représenter approximativement les centres des villages de la
Haute-Garonne (31), on
fera
departement = communes[communes.dep == "31"].copy()
departement['geometry'] = departement['geometry'].centroid
ax = departement.plot(figsize = (10,10), color = 'red', alpha = 0.4, zorder=2)
communes[communes['dep'] == "31"].plot(ax = ax, zorder=1, edgecolor = "black", facecolor="none",
color = None)
#ctx.add_basemap(ax, crs = stations.crs.to_string(), source = #ctx.providers.Stamen.Toner)

Gérer le système de projection
Précédemment, nous avons appliqué une méthode to_crs pour reprojeter
les données dans un système de projection différent de celui du fichier
d’origine:
communes = communes.to_crs(2154)
stations = stations.to_crs(2154)
Le système de projection est fondamental pour que la dimension spatiale soit bien interprétée par python. Un mauvais système de représentation
fausse l’appréciation visuelle mais peut aussi entraîner des erreurs dans
les calculs sur la dimension spatiale.
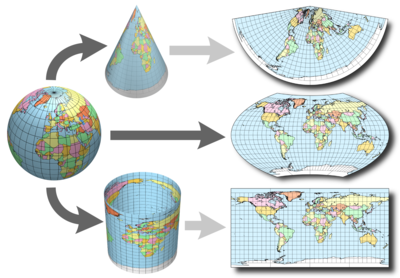
Ce post propose de riches éléments sur le sujet, notamment l’image suivante qui montre bien le principe d’une projection:
La documentation officielle de geopandas est également très bien faite sur le sujet. Elle fournit notamment l’avertissement suivant qu’il est bon d’avoir en tête:
Be aware that most of the time you don’t have to set a projection. Data loaded from a reputable source (using the geopandas.read_file() command) should always include projection information. You can see an objects current CRS through the GeoSeries.crs attribute.
From time to time, however, you may get data that does not include a projection. In this situation, you have to set the CRS so geopandas knows how to interpret the coordinates.
 Image empruntée à https://blog.chrislansdown.com/2020/01/17/a-great-map-projection-joke/
Image empruntée à https://blog.chrislansdown.com/2020/01/17/a-great-map-projection-joke/
Pour déterminer le système de projection d’une base de données, on peut vérifier l’attribut crs:
communes.crs
## {'init': 'epsg:4326'}
Les deux principales méthodes pour définir le système de projection utilisé sont:
df.set_crs: cette commande sert à préciser quel est le système de projection utilisé, c’est-à-dire comment les coordonnées (x,y) sont reliées à la surface terrestre. Cette commande ne doit pas être utilisée pour transformer le système de coordonnées, seulement pour le définir.df.to_crs: cette commande sert à projeter les points d’une géométrie dans une autre, c’est-à-dire à recalculer les coordonnées selon un autre système de projection. Par exemple, si on désire produire une carte avec un fondopenstreetmapsou une carte dynamiqueleafletà partir de données projetées en Lambert 93, il est nécessaire de re-projeter les données dans le système WGS 84 (code EPSG 4326). Ce site dédié aux projections géographiques peut-être utile pour retrouver le système de projection d’un fichier où il n’est pas indiqué.
La définition du système de projection se fait de la manière suivante (⚠ avant de le faire, se souvenir de l’avertissement !):
communes = communes.set_crs(2154)
Alors que la reprojection (projection Albers: 5070) s’obtient de la manière suivante:
communes[communes.dep != "97"].dissolve(by='dep', aggfunc='sum').to_crs(5070).plot()
On le voit, cela modifie totalement la représentation de l’objet dans l’espace. Clairement, cette projection n’est pas adaptée aux longitudes et lattitudes françaises. C’est normal, il s’agit d’une projection adaptée au continent nord-américain, et encore, pas dans son ensemble :
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
world[world.continent == "North America"].to_crs(5070).plot(alpha = 0.2, edgecolor = "k")
Joindre des données
Joindre données sur des attributs
Ce type de jointure se fait entre un objet géographique et un
deuxième objet, géographique ou non. A l’exception de la question
des géométries, il n’y a pas de différence par rapport à pandas.
La seule différence avec pandas est dans la dimension géographique.
Si on désire conserver la dimension géographique, il faut faire
attention à faire:
geopandas_object.merge(pandas_object)
Si on utilise deux objets géographiques mais ne désire conserver qu’une seule dimension géographique^[1], on fera
geopandas_object1.merge(geopandas_object2)
Seule la géométrie de l’objet de gauche sera conservée, même si on fait un right join.
^[1:] Il est techniquement possible d’avoir un DataFrame comportant plusieurs géographies. Par exemple une géométrie polygone et une géométrie point (le centroid). C’est néanmoins souvent compliqué à gérer et donc peu recommandable.
Joindre données sur dimension géographique
TO DO
Conseils
Les jointures spatiales peuvent être très gourmandes en ressources (car il peut être nécessaire de croiser toutes les géométries de x avec toutes les géométries de y). Voici deux conseils qui peuvent vous aider:
- Il est préférable de tester les jointures géographiques sur un petit échantillon de données, pour estimer le temps et les ressources nécessaires à la réalisation de la jointure.
- Il est parfois possible d'écrire une fonction qui réduit la taille du problème. Exemple: vous voulez déterminer dans quelle commune se situe un logement dont vous connaissez les coordonnées et le département; vous pouvez écrire une fonction qui réalise pour chaque département une jointure spatiale entre les logements situés dans ce département et les communes de ce département, puis empiler les 101 tables de sorties.